

ทีมปัญญาประดิษฐ์ DeepMind ของกูเกิล (ผู้สร้าง AlphaGo) โชว์ผลงานใหม่ WaveNetโมเดลปัญญาประดิษฐ์ที่สร้างเสียงสังเคราะห์ได้จากรูปแบบคลื่นเสียงของมนุษย์ สามารถใช้สร้างได้ทั้งเสียงพูด (speech) และเสียงดนตรี (music) จากการเรียนรู้ผ่าน deep learning
เป้าหมายหลักของ WaveNet ต้องการนำมาสร้างเสียงพูดสังเคราะห์ (text-to-speech หรือ TTS) ซึ่งปัจจุบัน ระบบสังเคราะห์เสียงพูด TTS ส่วนใหญ่เก็บเสียงพูดเป็นคำสั้นๆ แล้วนำเสียงมาต่อกันเป็นประโยค (มีชื่อเรียกว่า concatenative TTS) ซึ่งมีข้อเสียคือดัดแปลงเสียงได้ยาก เพราะต้องอัดเสียงใหม่ทั้งหมด
ในแวดวงจึงพัฒนาระบบเสียงสังเคราะห์ที่เรียกว่า parametric TTS ที่เปลี่ยนคุณสมบัติของเสียง (เช่น เพศหรืออายุของคนพูด) ได้จากพารามีเตอร์ที่ป้อนให้ แต่ข้อจำกัดของโมเดลนี้คือเสียงที่สังเคราะห์ได้ยังไม่เป็นธรรมชาติ (เมื่อเทียบกับ concatenative TTS)
WaveNet นำแนวคิดเรื่องการสร้างคลื่นเสียง (raw waveform) จาก AI เข้ามาปรับปรุง parametric TTS ให้ได้เสียงที่เป็นธรรมชาติมากขึ้น วิธีการคือเทรน AI ให้รู้จักรูปแบบของคลื่นเสียงโดยตรง ลักษณะเดียวกับ AI ที่ใช้สร้างรูปภาพที่ซับซ้อนขึ้นมาได้ด้วยโมเดล convolution neural network แบบหลายเลเยอร์
ขั้นตอนการทำงานของ WaveNet คืออัดเสียงพูดของมนุษย์ แล้วเทรน AI ให้เรียนรู้คลื่นเสียงแต่ละแบบไปเรื่อยๆ หลังจากนั้น AI จะสามารถสร้างคลื่นเสียงลักษณะคล้ายๆ กัน (แต่อาจฟังไม่รู้เรื่องเป็นคำๆ) ขึ้นมาได้ ซึ่งทีมงาน DeepMind ต้องนำไปรวมกับข้อความ (text) เพื่อแปลงเป็นเสียงพูดที่ฟังแล้วมีความหมายจริงๆ (ทีมงาน WaveNet ลองเอาไปสร้างเสียงดนตรีได้ด้วย โดยเทรนเสียงเปียโนให้ ผลก็ออกมาใช้ได้ เพราะไม่ต้องมีตัว text มาประกอบ)
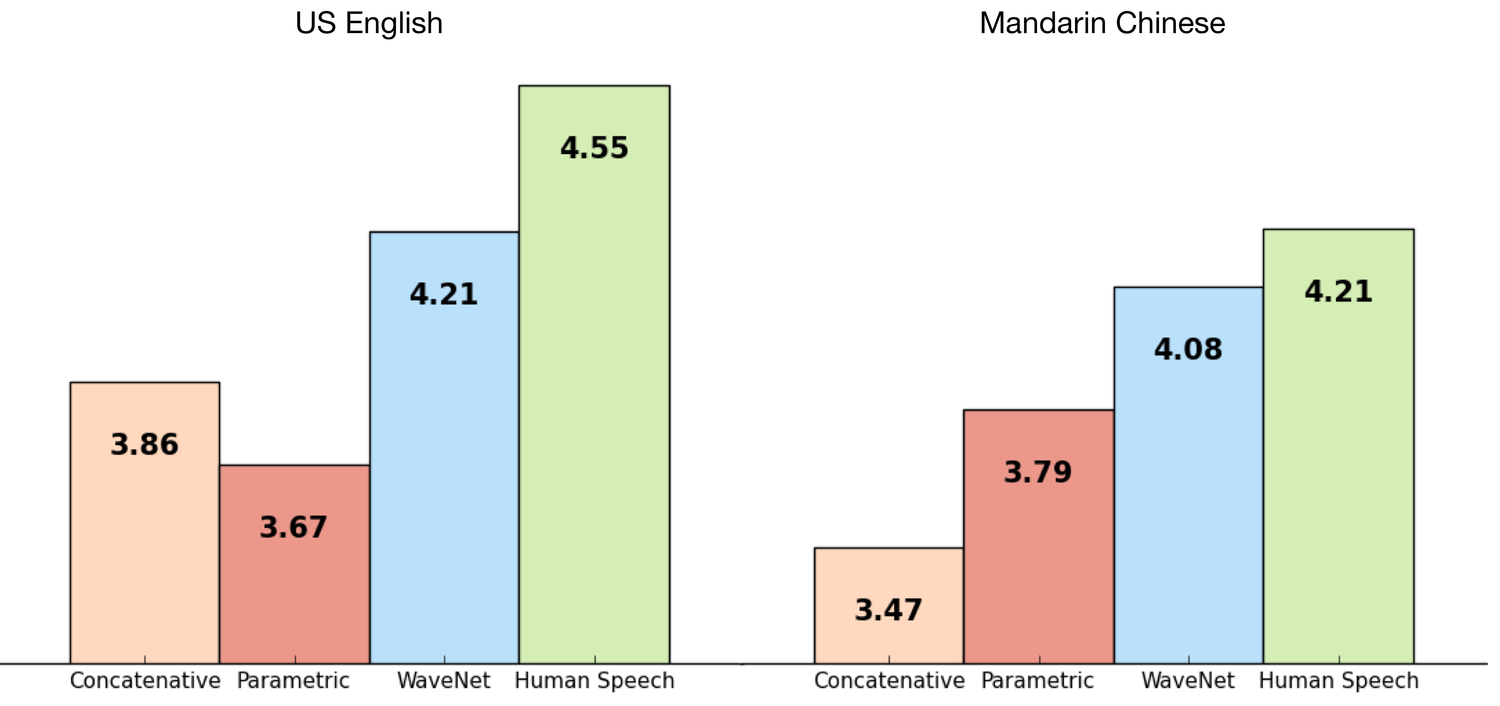
DeepMind ลองทดสอบ WaveNet (สีฟ้าในกราฟ) เทียบกับเสียงพูดจริงของมนุษย์ (สีเขียวในกราฟ) พบว่ามีความใกล้เคียงมากขึ้น เมื่อเทียบกับเสียงที่ได้จาก Google TTS ตัวที่ใช้ใน Android ปัจจุบัน (สีชมพูและสีแดง) ในภาพรวมแล้วประสิทธิภาพของ WaveNet ดีขึ้นกว่า Google TTS ถึง 50%
ใครสนใจลองฟังเสียงจาก WaveNet ก็เข้าไปทดสอบกันได้ตามลิงก์
ที่มา - DeepMind





Comments
สุดยอด !
ใกล้เคียงกับเสียงคนมากครับ
มันไม่เหมือนเสียงสังเคราะห์อีกต่อไป แต่เหมือนออกมาจากปากเลย
รู้สึกได้ถึงการแตะลิ้น และขยับปาก คงเหลือก็แต่การพูดตามอารมณ์ต่างๆ
ต่อไปถ้ามันฉลาดขึ้น คงแย่งงานมนุษย์น่าดู
แต่คิดอีกทีก็ดีเหมือนกัน นึกภาพว่าโทรหา 911 แล้วมีคนรับสายแน่นอนหรือโทรหาคอลเซ็นเตอร์ทั้งหลายแล้วไม่ต้องถือสายรอเป็นสิบๆนาที
โหดดดดดด
ถ้าสำเร็จงานภาคเสียงหนัง อนิเมะ คงเป็นอะไรที่สุดยอดไปเลย ต่อยอดด้วยการเรียบแบบน้ำเสียงจากภาษาต้นฉบับ แบบเสียงของคนแสดงต่างชาติแต่พูดไทยได้ จะรอวันนั้นนะถ้านายไม่ยึดโลกเราเสียก่อน
ให้เลือกว่าใครพากย์ตัวละครไหนได้นี้ชอบเลย
ใช้ SUB กลายเป็นเสียงได้เลยจะสุดยอดมาก
ถ้าทำอย่างนี้ได้จะดีมากๆ เลย แต่คนพากย์คงจะตกงานกันหมดแน่
+1
เดี๋ยวคงมีคนโหลดเสียงมิกุใส่ไป
ถ้าสมบูรณ์มากๆ อาจใช้ในหุ่นยนต์, Chat bot, ระบบ call center หรือใช้ในการก่ออาชญากรรมทางโทรศัพท์และทางการแชทอัตโนมัติจะทำได้ง่ายขึ้นด้วย พอเป็นแบบนี้ มันก็กลายเป็นดาบสองคมไปเลยในตัว
Get ready to work from now on.
Google มาแรงมาก
convolution neural network น่าจะเป็น convolutional neural network มากกว่านะครับ
แจ่มแมว
อิไต อ่า....คิมุจิ โอ้ววอ่า.... #ฝึกให้มันภาคหนังครับ
The Last Wizard Of Century.
กรี๊ดๆๆ จะได้ฟังเสียงคาวาอี๊ คืออยากให้มาพากษ์ไทยอนิเมะมากๆ บอกเลยพากษ์ไทยนิทำหมดอารมณ์ดูไปดูญี่ปุ่นเลยดีกว่า...
เสียงดนตรี ให้อารมณ์หัวร้อนมาก
เสียงเหมือนคนมาก
เอามาตั้งรับโทรศัพท์เวลาพ่อบ้านหนีเที่ยวได้จะดีมาก
ต่อไปถ้ามีเทปลับออกมาก็น่าสงสัยไว้ก่อน
ฟังแล้ว เสียงดูมีน้ำหนัก มีโทนเสียงต่ำสูง แบบที่ไม่ใช่เสียงโทนเดียวทื่อๆ ชอบๆ
ระบบความปลอดภัยที่ยืนยันด้วยคำสั่งเสียง ... สั่งยิงขีปนาวุธ -..-'
my blog
สัญญาณของ AI apocalyse